2025-11-01 从零构建大模型—通过微调遵循人类指令
发布于 2025年11月01日 • 3 分钟 • 589 字
Table of contents
终于来到这本书的最后一章啦。
这本书的整体脉络非常清晰:从最初的输入处理,逐步深入到自注意力机制、因果自注意力,再到亲手实现一个大模型,接着进行预训练,并最终完成分类微调和指令微调。完成整个学习过程后,确实感到收获颇丰。(个人觉得第三、四章的内容最为关键)
当然我也清楚,还有很多细节需要进一步补充,比如训练过程中的各种技巧、多卡并行操作,以及参数高效微调等等。这些都是我接下来会继续学习的内容。
接下来是本章的内容:
预训练后的大模型能够实现文本补全——给定一个文本片段作为输入,模型能够继续生成后续内容。 但如果希望模型能够遵循指令、生成合理回复,就需要进行指令微调。
这一部分的实现流程和上一章很相似,主要区别在于数据集的格式。依然分为三个阶段来完成。
第一阶段:数据准备
包括下载数据集、进行数据预处理以及构建数据加载器。
第二阶段:模型微调
包括加载预训练大语言模型、执行指令微调以及监控模型损失。
第三阶段:评估大语言模型
包括提取模型回复、进行量化评估以及对生成内容打分。
第一阶段:数据准备
1. 下载数据
可以使用网上已有的数据集:
url = "https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/main/ch07/01_main-chapter-code/instruction-data.json"
指令微调所需的数据是“输入-输出”对。例如:
{'instruction': 'Identify the correct spelling of the following word.',
'input': 'Ocassion',
'output': "The correct spelling is 'Occasion.'"}
为了适配大模型的输入格式,还需要将数据加工成如下形式。这种“###”分隔的格式,是从概率角度帮助模型识别结构:
Below is an instruction that describe a task. Write a response that appropriately
complete the request.
### Instruction:
Identify the correct spelling of the following word.
### Input:
Ocassion
### Output
The correct spelling is 'Occasion'.
2. 数据集预处理
数据下载后,需要将样本填充至相同长度,并进行批次处理。
可以通过 PyTorch 的 DataLoader 类来构建训练批次。由于预处理逻辑较为复杂,这里需要自定义一个 collate_fn 函数。
主要步骤如下:
- 使用提示词模板格式化数据
- 对格式化文本进行词元化(tokenize)
- 使用填充词元统一序列长度
- 创建目标词元 ID 用于训练
- 使用占位符替换部分填充词元
其中有一个关键操作:
inputs = torch.tensor(padded[:-1]) targets = torch.tensor(padded[1:])
这个操作的意思是:向左移动一个词元的位置,然后将输入序列的第一个词元忽略,最后在尾部加入结束符词元即可得到其对应的目标序列。结束词元设为-100,这样在计算损失时可以排除填充词元的影响,确保只有有效数据参与模型学习。
class InstructionDataset(Dataset):
def __init__(self, data, tokenizer):
self.data = data
self.tokenizer = tokenizer
self.encoded_texts = []
for entry in data:
input_text, full_formatted_text = format_input(entry)
encoded_text = self.tokenizer.encode(full_formatted_text)
self.encoded_texts.append(encoded_text)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.encoded_texts[idx]
def custom_collate_fn(batch,pad_token_id=50256,
ignore_index=-100, allowed_max_length=None):
batch_max_len = max(len(seq)+1 for seq in batch)
inputs_list,targets_list =[],[]
for item in batch:
new_item = item.copy()
new_item += [pad_token_id]
padded = new_item + [pad_token_id] * (batch_max_len - len(new_item))
inputs = torch.tensor(padded[:-1])
targets = torch.tensor(padded[1:])
mask = targets ==pad_token_id
indices = torch.nonzero(mask).squeeze()
if indices.numel()>1:
targets[indices[1:]] = ignore_index
if allowed_max_length is not None:
inputs = inputs[:allowed_max_length]
targets = targets[:allowed_max_length]
inputs_list.append(inputs)
targets_list.append(targets)
inputs_tensor = torch.stack(inputs_list)
targets_tensor = torch.stack(targets_list)
return inputs_tensor, targets_tensor
from functools import partial
customized_collate_fn = partial(
custom_collate_fn,
allowed_max_length=1024
)
3. 创建数据加载器
train_dataset = InstructionDataset(train_data, tokenizer)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
collate_fn=customized_collate_fn
)
第二阶段:模型微调
1. 模型初始化
使用在《徒手组装GPT》章节中构建的 GPTModel 类。这里建议使用较大的模型,因为小模型的指令遵循能力通常较弱。
BASE_CONFIG = {
"vocab_size": 50257,
"context_length": 1024,
"drop_rate": 0.0,
"qkv_bias": True
}
models_config = {
"gpt2": {"emb_dim":768,"n_heads":12, "n_layers":12,},
"gpt2-medium": {"emb_dim":1024,"n_heads":16, "n_layers":24,},
"gpt2-large": {"emb_dim":1280,"n_heads":20, "n_layers":36,},
"gpt2-xl": {"emb_dim":1600,"n_heads":25, "n_layers":48,},
}
CHOOSE_MODEL= "gpt2-xl"
BASE_CONFIG.update(models_config[CHOOSE_MODEL])
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
model = GPTModel(BASE_CONFIG)
2. 加载预训练权重
这部分在之前的章节中已经实现过:
params = build_openai_numpy_dict(CHOOSE_MODEL)
load_weights_into_gpt(model, params)
model.eval()
3. 看模型微调之前的结果和loss
输入文本为:
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence using a simile.
### Input:
The car is very fast.
模型回复为:
dividendJenn Growing clans readspar goodness264264 Monthescap woes Neither experienced Surprisinglyortalityonductorassies Athletics Anniversary descriptive descriptive biases rookies Neither Ming Isleneapolis endors Height outreach floods LU Part
可以看出,未经微调的大语言模型还不能正确遵循指令,只能进行文本补全。
初始损失为:
Training loss: 10.981371307373047
Validation loss: 10.983566093444825
4 . 训练代码实现
在每次循环中,我们计算每个训练批次的损失,获取梯度,并用其更新模型权重,从而逐步降低训练损失。
计算模型损失
def calc_loss_batch(input_batch, output_batch, model, device):
input_batch = input_batch.to(device)
output_batch = output_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(logits.flatten(0,1), output_batch.flatten())
return loss
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss =0.0
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches =len(data_loader)
else:
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
else:
break
return total_loss / num_batches
def evaluate_model(model, train_loader,val_loader,device,eval_iter):
model.eval()
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)
model.train()
return train_loss, val_loss
训练步骤
- 遍历训练轮次(一轮就是完整地遍历一次训练集)
- 在每个训练轮次中遍历批次(批次数量由训练集大小除以每个批次的大小确定)
- 从上一个批次迭代中重置损失函数
- 计算当前批次的损失
- 反向传播以计算损失梯度
- 使用损失梯度更新模型权重
- 打印训练集和验证集的损失(可选)
训练代码
代码很好写,就是上面的七个步骤:
def train_model_simple(model, train_loader, val_loader,
optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
train_losses, val_losses, track_tokens_seen = [], [], []
tokens_seen, global_step = 0, -1
for epoch in range(num_epochs):
model.train()
for input_batch, target_batch in train_loader:
optimizer.zero_grad(set_to_none=True)
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward()
optimizer.step()
tokens_seen += input_batch.numel()
global_step += 1
# --- periodic evaluation ---
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"Ep {epoch + 1} (step {global_step:06d}): "
f"train loss {train_loss:.3f}, val loss {val_loss:.3f}")
save_dir = "results/plots"
os.makedirs(save_dir, exist_ok=True)
plot_path = os.path.join(save_dir, f"training_loss_plot_{CHOOSE_MODEL}.png")
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, track_tokens_seen, train_losses, val_losses,save_path=plot_path)
return train_losses, val_losses, track_tokens_seen
运行训练
由于使用的是 gpt2-xl 模型,使用多张 GPU 运行以避免内存不足:
CUDA_VISIBLE_DEVICES=2,3,5 python /home/data/sophia/learning_llm/llm_from_scratch/chapter_7
_instruct_tuning/finetune.py
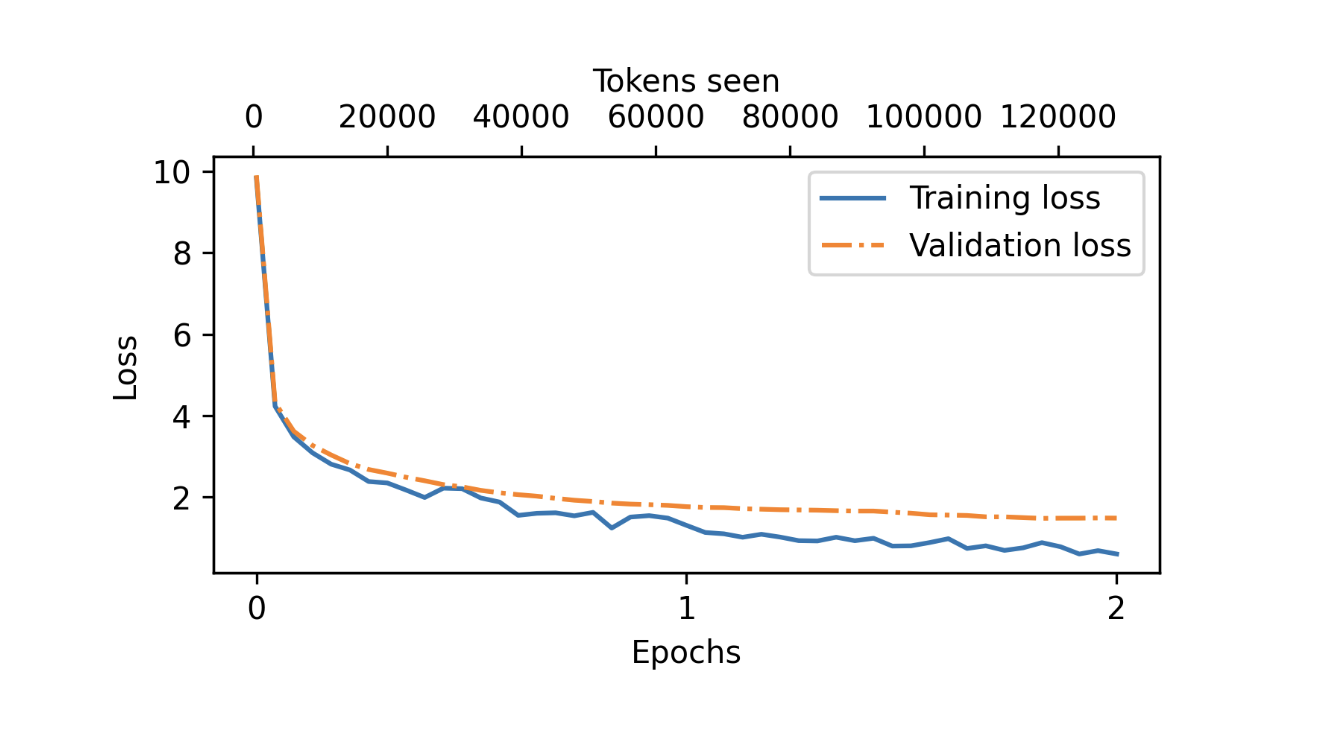
下图展示了训练两个 epoch 后的损失曲线。实线表示训练损失,呈现快速下降后趋于稳定的趋势;虚线表示验证损失,模式类似,说明模型训练是有效的。
在新数据上使用模型进行推理
虽然模型没有回答正确,但回复的格式和内容已经比微调前规范许多。
第三阶段:评估大语言模型
常见的模型评估方法是基于公开基准数据集进行测试。此外,也可以使用另一个大语言模型(例如通过 ollama 启动的 Llama 3)对测试数据进行自动评估。
书中对此有具体示例,这里不再赘述。