2025-08-17 从零构建大模型——注意力机制
发布于 2025年08月17日 • 3 分钟 • 538 字
Table of contents
背景
编码器-解码器
编码器将源语言的一串词元序列作为输入,并通过隐藏状态(一个中间神经网络层)编码整个输入序列的压缩表示(可以理解为嵌入)。然后,解码器利用其当前的隐藏状态开始逐个词元进行解码生成。
编码器-解码器RNN的缺陷:在解码阶段,RNN无法直接访问编码器中的早期隐藏状态,它只能依赖当前的隐藏状态。这可能导致上下文丢失,特别是在依赖关系可能跨越较长的距离的句子中。
构建大语言模型的三个阶段
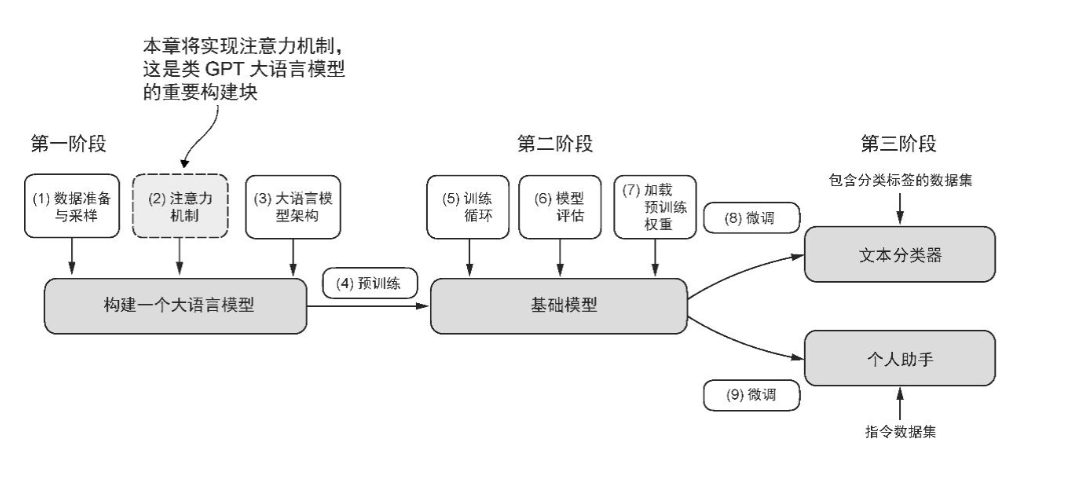
(图来源于书籍)
这张图画得很清晰,第三章的主要学习注意力机制。
学习目标
实现4种注意力机制
- 简化版的自注意力机制
- 加入可训练的权重的自注意力机制
- 因果注意力机制
- 多头注意力机制
简化版的自注意力机制
关键概念
- 注意力机制:对于输出,某些输入词元比其他词元更重要。重要性由注意力权重决定。
- “自”是什么意思:
- 上下文向量是什么?
- 上下文向量怎么计算?
实践
import torch
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts (x^3)
[0.22, 0.58, 0.33], # with (x^4)
[0.77, 0.25, 0.10], # one (x^5)
[0.05, 0.80, 0.55]] # step (x^6)
)
print(inputs.shape[0])
query = inputs[1]
attn_scores = torch.empty(inputs.shape[0],inputs.shape[0])
attn_scores = inputs @ inputs.T
print(attn_scores)
attn_weights = torch.softmax(attn_scores, dim=-1)
print("Attention weights:", attn_weights)
print("Sum:", attn_weights.sum(dim=-1))
all_context_vecs = attn_weights @ inputs
print(all_context_vecs)
带可训练权重的自注意力机制(缩放点积注意力 scaled dot-product attention)
关键概念
-
缩放点积注意力
-
为什么要用Query 、Key和Value?
实践
v1版:用nn.Parameter
import torch.nn as nn
class SelfAttention_v1(nn.Module):
def __init__(self, d_in, d_out):
super().__init__()
self.W_query = nn.Parameter(torch.rand(d_in, d_out))
self.W_key = nn.Parameter(torch.rand(d_in, d_out))
self.W_value = nn.Parameter(torch.rand(d_in, d_out))
def forward(self, x):
keys = x @ self.W_key
queries = x @ self.W_query
values = x @ self.W_value
attention_scores = queries @ keys.T
attention_weights = torch.soft(attention_scores/keys.shape[-1]**0.5, dim=-1)
context_vec = attention_weights @ values
return context_vec
v2版:用nn.Linear
torch.nn.Parameter仅是一个静态矩阵,若需实现线性变换(如 y = x @ W_query),需手动编写矩阵乘法。nn.Linear是PyTorch 提供的全连接层,自动管理权重和偏置,在初始化策略上与Parameter不一样,因此这两个类对于同一个inputs结果会不一样。
class SelfAttention_v2(nn.Module):
def __init__(self, d_in, d_out):
super().__init__()
self.W_query = nn.Linear(d_in, d_out)
self.W_key = nn.Linear(d_in, d_out)
self.W_value = nn.Linear(d_in, d_out)
def forward(self, x):
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attention_scores = queries @ keys.T
attention_weights = torch.softmax(attention_scores/keys.shape[-1]**0.5, dim=-1)
context_vec = attention_weights @ values
return context_vec
因果注意力机制
关键概念
- 因果注意力(也称为掩码注意力)是一种特殊的自注意力形式。它限制模型在处理任何给定词元时,只能基于序列中的先前和当前输入来计算注意力分数,而标准的自注意力机制可以一次性访问整个输入序列
- 利用dropout掩码额外的注意力权重
实践
- context_length 决定了模型能处理的最长输入序列,用于生成掩码矩阵。
- attention_scores = queries @ keys.transpose(1,2) 将批维度保持在第一位。
- self.register_buffer 创建一个上三角掩码矩阵(upper triangular mask),并将其注册为模型的缓冲区。
- self.mask.bool() 是将 self.mask(一个数值矩阵)转换为 布尔矩阵(Boolean Mask),用于指示哪些位置的注意力分数需要被屏蔽(替换为 -inf),[:num_tokens, :num_tokens]表示截取适配当前序列长度的掩码。
- attention_scores.masked_fill_ 带有尾随下划线的操作会就地执行,将True的位置替换为-inf。
import torch.nn as nn
import torch
class CausalAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, qkv_bias=False):
super().__init__()
self.W_query = nn.Linear(d_in, d_out,bias= qkv_bias)
self.W_key = nn.Linear(d_in, d_out,bias= qkv_bias)
self.W_value = nn.Linear(d_in, d_out,bias= qkv_bias)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
'mask',
torch.triu(torch.ones(context_length, context_length), diagonal=1)
)
def forward(self, x):
b,num_tokens,d_in = x.shape
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
attention_scores = queries @ keys.transpose(1,2)
attention_scores.masked_fill_(self.mask.bool()[:num_tokens, :num_tokens], -torch.inf)
attention_weights = torch.softmax(
attention_scores/keys.shape[-1]**0.5, dim=-1
)
attention_weights = self.dropout(attention_weights)
context_vec = attention_weights @ values
return context_vec
多头注意力机制
关键概念
多头注意力的主要思想是多次(并行)运行注意力机制,每次使用学到的不同的线性投影。
例如:对于有两个头的多头注意力机制,会使用两组初始权重矩阵,两个查询矩阵,两组注意力权重矩阵,会得到两组上下文向量。
多头注意力机制是指有多组注意力权重。
实践
v1版:用for循环
import torch
from attention_3 import CausalAttention
class MultiHeadAttentionWrapper(nn.Module):
def __init__(self, d_in, d_out, context_length,dropout, num_heads, qkv_bias=False):
super().__init__()
self.heads = nn.ModuleList(
[CausalAttention(d_in, d_out,context_length,dropout, qkv_bias) for _ in range(num_heads)]
)
def forward(self,x):
return torch.cat([head(x) for head in self.heads], dim=-1)
v2版:用批量矩阵乘法
- 对 keys、queries 和 values 进行维度重塑(reshape):将 (b, num_tokens, d_model) 重塑为 (b, num_tokens, num_heads, head_dim)。
- self.out_proj 的作用。多头注意力中,每个头独立计算特征(如 head1 关注语法,head2 关注语义),直接拼接(torch.cat)只是简单堆叠,而 out_proj 通过权重矩阵动态混合这些特征。
import torch.nn as nn
import torch
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), "d_out must be divisible by num_heads"
self.d_out=d_out
self.num_heads = num_heads
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
'mask',
torch.triu(torch.ones(context_length, context_length), diagonal=1)
)
def forward(self,x):
b,num_tokens,d_in = x.shape
keys = self.W_key(x)
queries = self.W_query(x)
values = self.W_value(x)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
keys = keys.transpose(1,2)
queries = queries.transpose(1,2)
values = values.transpose(1,2)
attention_scores = queries @ keys.transpose(2,3)
attention_scores.masked_fill_(self.mask.bool()[:num_tokens, :num_tokens], -torch.inf)
attention_weights = torch.softmax(
attention_scores/keys.shape[-1]**0.5, dim=-1
)
attention_weights = self.dropout(attention_weights)
context_vec = attention_weights @ values
context_vec = context_vec.transpose(1,2)
context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out)
context_vec = self.out_proj(context_vec)
return context_vec
多头注意力机制代码例子
设batch_size=2,num_tokens=6,d_in=512,d_out=512,num_heads=8,head_dim=64。
- 输入形状
- 生成 Q/K/V
- 拆分成多头(view + transpose)
- 计算注意力分数
- 应用因果掩码
- 计算注意力权重
- 计算上下文向量
- 合并多头输出
其他
softmax函数可以保证注意力权重总是正值,这使得输出可以被解释为概率或相对重要性,其中权重越高表示重要程度越高。