2025-07-26 论文阅读 LongCite Enabling LLMs to Generate Fine-grained Citations in Long-context QA
发布于 2025年07月26日 • 2 分钟 • 264 字
Table of contents
大模型的幻觉一直没有被解决,在有上下文的情况下最直接的应对方式就是让它“自证出处”。在调研的过程中,我发现,目前主流做法要么照搬 DeepSeek-R1 的 prompt 模板让模型当场给出引用,要么事后用规则再捞一遍参考文献。但是这篇论文走了另一条路:拿一个 8B/9B 的小模型,针对“长上下文问答 + 引用生成”做微调。
这个一年前的论文微调的小模型应该打不过现有的大模型,但是在构造数据集、构造评估的方法等方面都给了我启发。
原文地址:https://arxiv.org/abs/2409.02897
背景
- 长文本大模型用来做信息抽取或者总结,但是因为缺乏引用,无法支撑观点。
- RAG因为缺少完整的上下文信息导致答案质量下降,post-hoc方法则因流程复杂延长用户等待时间。
- 虽然有的web search能够提供引用,但是指向整个页面,粒度太粗。而用户需要知道知道具体的引用段落或者句子。
Contribution
- 提出了LongBench-Cite,一个带引用的长上下文问答的benchmark
- 提出了CoF,一种用大模型自动构建高质量长上下文数据集的pipeline
- 构造了数据集 LongCite-45k
- 训练了模型 LongCite-8B 和 LongCite-9B
细节
Benchmark LongBench-Cite
1. 构造带引用的长上下文问答任务
给定语料$D$和查询$q$,大模型需要返回一个响应$A$,该响应由n个陈述$s_1$,…,$s_n$组成,每个陈述$s_i$有一个引用列表$Ci = {c_{i,1}, c_{i,2},… }$,里面引用了D的片段。
D表示Document,q表示query,A表示Answer,s表示statement,C表示citation。
大模型需要把它的结果分割成不同的陈述,格式为<statement>content</statement>。
有两种粒度的引用,这里主要考虑句子级别的引用:
- 块级引用 Chunk-level citation
- 句级引用 Setence-level citation
2. 构建基准测试:LongBench-Cite
整合了现有的以下的两个Benchmark的数据。
- LongBench
- LongBench-Chat
3. 评估
LongBench-Cite基于两个维度进行评估:
-
正确性(Correctness):大模型的回答是否准确和全面
-
引用质量(Citation quality):回答是否完全能由引用的片段得出,同时没有不相关的片段被引用,并且被引用的片段是细粒度的。 3.1 “正确性”的评估方法
-
首先把回答里面引用相关的部分移除,让大模型(GPT-4o)基于query和正确答案来评分,采用之前别人的论文提出来的方法来进行。
-
为了看增加引用是否会伤害模型的长上下文问答的性能,增加了correctness ratio的计算。 C 和 C_{LQA} 分别表示带引用和不带引用的正确率,不带引用的做法是直接把语料和query给大模型,生成回复。
3.2 “引用质量”的评估方法
- 计算 Citation Recall
- 计算 Citation Precision 对于每个引用,判断它是否是相关的引用(1/0表示相关/不相关),然后计算平均值。这个过程也是用GPT-4o来做的。
- 计算 Citation F1 使用 $F1 = (2 · P · R)/(P + R)$ 来计算
- 用 Citation Length来评估粗细粒度
CoF(Coarse to Fine)
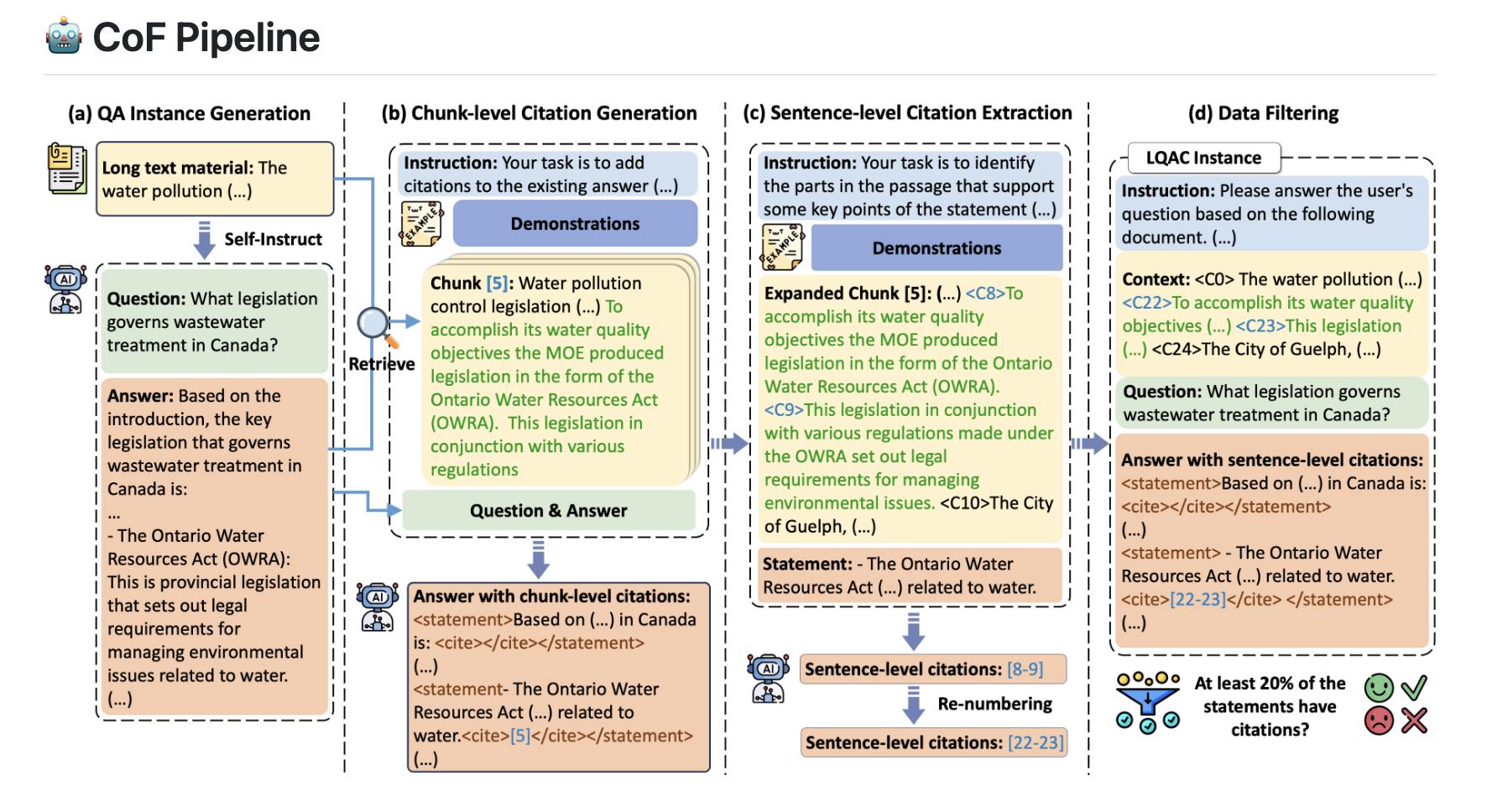
用大模型来构造高质量的长上下文问答数据的方法,粒度由粗到细,包含以下四步:
-
QA Instance Generation 问答对生成 给定一个长的语料,CoF首先用大模型来生成查询query和答案,这一步采用的方法是Self-Instruct。 Self-Instruct是这样做的:
-
Chunk-level Citation Generation 将语料切分成128 个token的chunks,使用答案中的句子从语料的chunks中检索总计k个。然后将这些按上下文位置排序的文本块,连同查询与答案一并输入大型语言模型,让它在答案中添加粗粒度的chunk level引用。
-
Sentence-level Citation Extraction 首先通过将每个被引用的块与其前后的块连接起来进行扩展。然后在扩展后的区块中保留并编号完整的句子,并指示LLM从该区块中提取细粒度的支持片段,输出如[6-8]这样的数字范围(表示第6到第8句),或者在区块中未找到支持片段时输出“无相关信息”。最后移除不规范的引用。
-
Data Filtering 若答案中少于20%的陈述包含引用来源,舍弃该数据。 思考
-
为什么让大模型不一次性生成带引用的回答? 因为带引用会影响模型生成回答的质量。所以首先生成QA对,再逐步生成有粗到细的引用。
-
为什么要先生成块级引用,再生成句级引用? 因为相较于逐句生成引用,这种聚合所有检索文本块并一次性生成引用的方法,不仅能减少大型语言模型的调用次数,还能因陈述句间的高度关联性而提升引用的召回率。
-
为什么舍弃引用少于20%的陈述? 因为当答案引用过少时,推定其缺乏充分的语境事实依据,可能过度依赖大语言模型的内部知识——这种情况往往会导致幻觉性内容的产生。
CoF与其他的长上下文问答策略的对比
前两个属于单次方法 one-pass methods,后三个(包括CoF)属于后处理方法 post-hoc methods。
- LAC-C/LAC-S:LLM读取整个上下文,并一次性生成响应以及块级/句级引用。
- RAC-C/RAC-S:LLM读取使用查询检索到的前k个块/句子,并一次性生成响应以及块级/句级引用。
- post-LC-C/post-LC-S:LLM首先通过普通的长上下文问答生成响应,然后通过从整个上下文中查找支持证据,将块级/句级引用添加到响应中。
- post-RC-C/post-RC-S:LLM首先通过普通的长上下文问答生成响应,然后使用响应从上下文中检索约k个块/句子,并通过从检索到的文本中查找支持证据,添加块级/句级引用(类似于CoF的步骤2)。
- CoF:LLM首先通过普通的长上下文问答生成响应,然后通过从整个上下文中查找支持证据,逐步生成块级和句级引用,添加到响应中。 对比总结:
- 后处理方法优于单词方法
- 在各类后处理方法中,CoF实现了最高的引用F1值和相对较短的引用长度。此外,CoF相对于post-RC-C的优越性表明,句子级引用提取步骤能有效定位支撑句并过滤无关文本块。虽然post-RC-S的引用长度(49)比CoF(89)更短,但是基于直接检索的生成会导致过多不连续的引用编号,给后续训练带来困难。
数据集 LongCite-45k
用CoF方法构造了数据集 LongCite-45k。
- 从GLM-4训练的文本中收集了50k个文档,覆盖9个不同的类别,包括书籍、学术论文、百科全书和代码等,语言为中文和英文,长度为256到128k 个tokens。
- 使用GLM-4和Zhipu Embedding-v2 作为检索模型,生成44600个高质量的长文本问答对。
- 每一个问答对都由输入和输出两部分组成。输入为task instruction、document和query。输出为answer和sentence-level citations。
模型 LongCite-8B 和 LongCite-9B
训练目的:大模型在一次问答里能生成准确的回复和引用。
数据:将LongCite-45k和ShareGPT的76k general SFT数据组合,作为微调模型的输入。
模型:分别在Llama-3.1-8B和GLM-4-9B 微调,训练出模型模型 LongCite-8B和LongCite-9B。
训练细节:
- 所有模型均采用4个节点进行训练,每个节点配备8块H800 80G GPU
- 采用Megatron-LM框架配合上下文并行技术,以支持最高128k标记的训练序列长度
- 通过带损失加权的打包训练方法提升训练效率
- 批次大小设置为8,学习率设为1e-5
- 每个模型训练4000步,约相当于2个训练周期,耗时18小时
评估和结果
- 开源大语言模型,尤其是小参数模型,引用质量较差,并且明显落后于闭源模型。 虽然其正确率接近商业版,但开源模型在为陈述生成引用时,明显更难。原因可能是 (1)开源模型指令遵循能力和上下文学习能力不足 。(例如,不遵循约定的格式进行生成)。(2)开源模型的证据搜索能力较弱。(例如,无法为某些陈述找到引用;仅能获取部分引用;获取的引用是无关的)
- 商业大语言模型的引用质量依然不足。
- 让大模型在一次问答中同时生成回复和引用会损害它的长上下文问答性能。 这个从correctness ratio小于100%可以看出。这个可能是因为带引用的长文本问答的数据分布和标准长文本问答的数据分布不同。
- 微调后的模型的效果
人类评估
为了验证使用GPT-4o自动评估引文质量的结果与人类判断的相关性,对三个模型进行了人工评估:GLM-4、LongCite-8B和LongCite-9B。
具体做法:
-
将其在LongBench-Chat上的150条回答(包含1,064个陈述和909条引用)进行匿名化处理,并按照与GPT-4o评估相同的标准,人工标注了引文召回率和精确率。
-
将GPT-4o评估结果与ALCE进行了对比,ALCE采用自然语言推理模型TRUE来测量引文召回率和精确率。 结果:
-
GPT-4o的评估结果(排序)与人类的评估结果(排序)保持一致
-
GPT-4o的打分比人类的更低,可能是因为段落中出现的指示代词让大模型混淆。(做指代消解maybe可以解决这个问题)
-
把 GPT-4o 打的分数和人类专家打的分数去算 kappa,结果比 ALCE 这组基线高很多,说明 GPT-4o 跟人类专家意见更一致。(Cohen’s kappa 是衡量“两个人(或两个系统)打分一致性”的统计量,越接近 1 越一致。)
消融实验
- 为了说明长上下文问答能力不是来自于长上下文的微调,作为对比,用同一批数据(不带instruct和引用)训练出模型LongSFT-8B/9B,与LongCite-8B/9B 对比。
- 比较和CoF旗鼓相当的post-RAC-S 策略,对post-RAC-S构造的数据同样训练出9B模型对比,发现它的引用更差,可能是因为post RAC-S阶段直接调用了上下文中的非相邻句子,导致出现大量不连续的引用编号(如[3][7][15]…)。
- 探索正确性和引用质量的相关性,把 LongCite-9B 对 LongBench-Cite的回复分为3组,可以看出回复的正确性越高,引用质量也越高。
术语和概念
ALCE: Automatic Long-form Citation Evaluation 自动长文本引用评估
https://arxiv.org/abs/2305.14627
使用三个公开的长篇问答数据集作为评测载体,评测准确性,流畅性和引用质量
- ASQA(Ambiguous Short-answer QA 的长篇扩展) 特点:问题本身存在歧义,需要综合多份文档给出多个视角的长答案;语料以 2018/12/20 维基百科快照为主。
- QAMPARI 特点:典型的事实罗列型问题,答案通常是跨段落实体列表(如“列出某演员参演的全部电影”);同样基于维基百科。
- ELI5(Explain Like I’m Five) 特点:来自 Reddit 的 how/why/what 类问题,答案较长且主题多样;检索语料使用 Sphere(Common Crawl 的过滤版本)。
Self-Instruct
https://aclanthology.org/2023.acl-long.754.pdf
先用极少量人工种子指令,让大模型自己反复生成“指令-输入-输出”三元组,再经自动过滤,低成本地构建大规模指令微调数据。
ShareGPT
用户把与 ChatGPT 的真实多轮对话一键导出为 JSON,形成大量高质量“用户-助手”对话样本。该格式以 {“conversations”: [{“from”:“user”, “value”:…}, {“from”:“assistant”, “value”:…}, …]} 存储,被广泛用于训练多轮对话模型或作为通用 SFT 数据。
https://lmsys.org/blog/2023-03-30-vicuna/ 文章的作者用 ShareGPT 网站公开的 7 万条真实用户-ChatGPT 对话 直接对 LLaMA 做指令微调,得到 Vicuna-13B,成本仅约 $300。