2025-06-26 论文阅读 Qwen3 Embedding
发布于 2025年06月26日 • 4 分钟 • 734 字
Table of contents
论文地址:https://arxiv.org/pdf/2506.05176
Contribution
- 基于合成数据的multi-stage训练
- 构建高质量合成数据
- 引入模型合并(model merging)
细节
模型
Embedding Models
- 所有嵌入模型均基于 Qwen3 基座大模型构建;
- 使用带因果注意力(causal attention)的解码式架构;
- 在输入序列的末尾添加 [EOS],使用其最终一层 hidden state 作为 embedding 表示;
- 支持带指令输入(instruction),格式为: {Instruction} {Query}<|endoftext|>;
- 官方实验显示:相比无 instruction,指令式输入能显著提升效果;
- 支持 MRL。
Reranking Models
- 采用 point-wise reranking with LLMs within a single context:point-wise reranking是指 大型语言模型会对每个候选项单独评估其与查询的相关性,给出一个分数,然后根据这些分数进行排序。
- 支持 instruction 输入,prompt 格式如下:
<|im_start|>system
Judge whether the Document meets the requirements based on the Query and the
Instruct provided. Note that the answer can only be "yes" or
"no".<|im_end|>
, →, →
<|im_start|>user
<Instruct>: {Instruction}
<Query>: {Query}
<Document>: {Document}<|im_end|>
<|im_start|>assistant
<think>\n\n</think>\n\n
训练
训练目标
Embedding 模型采用 InfoNCE 对比损失
$$Loss= -log \frac{ \exp(sim(x_i,x_i^+)/\tau) }{\sum_{j=1}^K \exp(sim(x_i, x_i^{-j})/\tau) }$$
- InfoNCE loss 的目标是最大化正样本对的相似度,同时最小化负样本对的相似度。
- 负样本包括硬负样本、批内负样本等 Reranking 模型采用 SFT(二分类交叉熵)损失
$$L_{reranking}= -log p(l \mid P(q,d))$$
- 通过SFT 训练 LLM 作为一个判别器,让它逐项评估候选段落是否与查询匹配。这种 point-wise reranking 方法不要求文档之间直接比较,仅需模型判断每个文档的相关性强弱。
- 优化目标是最大化模型给正确标签(yes/no)打的概率,也就是:
- 公式说明
Multi-stage training
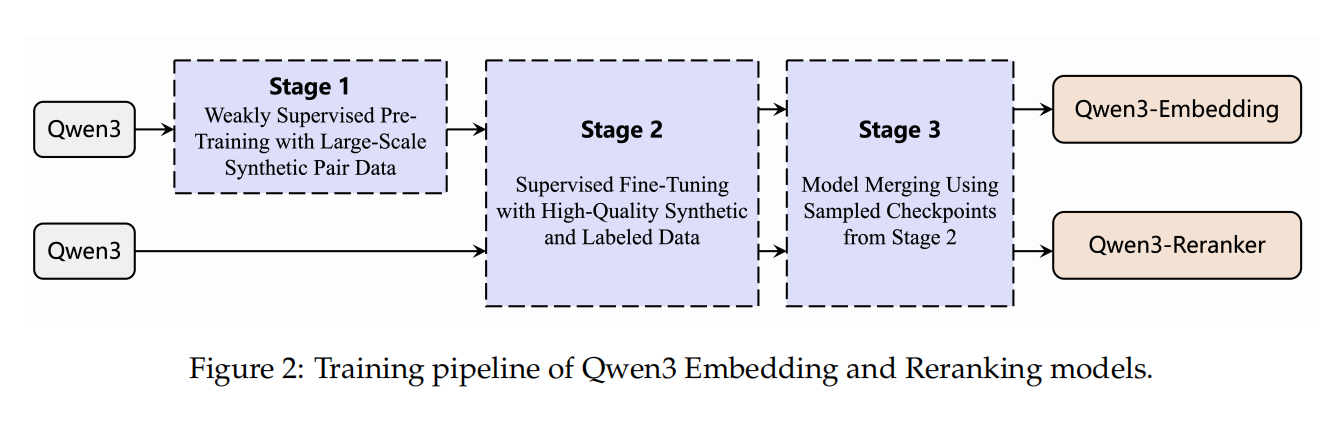
分为三阶段:
第一阶段:大规模的合成数据驱动的弱监督学习
Large-Scale Synthetic Data-Driven Weak Supervision Training
之前的GTE, E5, BGE models的数据主要来源于开源社区,Qwen3 的创新点在于使用基座模型来合成数据。根据不同维度的需要来生成,例如task, language, length和difficulty。与开源数据相比,合成数据更加可控,具有多样性。
第二阶段:SFT阶段利用高质量合成数据进行监督学习
High-Quality Synthetic Data Utilization in Supervised Fine Tuning
对筛选出的高质量合成数据(相似度 > 0.7)和公开监督数据集(如 MS MARCO、MIRACL 等)进行监督训练。
第三阶段:模型合并(Model Merging)
在SFT之后,对筛选出的高质量合成数据(相似度 > 0.7)和公开监督数据集(如 MS MARCO、MIRACL 等)进行监督训练。
注意:
Reranking模型的训练补不包含第一阶段的弱监督训练。
数据合成
Qwen3 的训练体系引入了四类任务合成数据:
- Retrieval(信息检索)
- Bitext Mining(比对挖掘)
- Classification(分类)
- Semantic Textual Similarity(STS,语义文本相似度) 数据合成使用的模型为 Qwen3-32B,语料来源是Qwen3 基座模型预训练阶段的多语言数据集。
以Retrieval 任务数据合成为例
数据合成分为两个阶段:
- 配置阶段(Configuration) Template 如下:
Given a **Passage** and **Character**, select the appropriate option from
three fields: Character, Question_Type, Difficulty, and return the output
in JSON format.
First, select the Character who are likely to be interested in the Passage
from the candidates. Then select the Question_Type that the Character
might ask about the Passage; Finally, choose the Difficulty of the
possible question based on the Passage, the Character, and the
Question_Type.
Character: Given by input **Character**
Question_Type:
- keywords: ...
- acquire_knowledge: ...
- summary: ...
- yes_or_no: ...
- background: ...
Difficulty:
- high_school: ...
- university: ...
- phd: ...
Here are some examples
<Example1> <Example2> <Example3>
Now, generate the **output** based on the **Passage** and **Character** from
user, the **Passage** will be in {language} language and the **Character**
will be in English.
Ensure to generate only the JSON output with content in English.
**Passage**:
{passage}
**Character**:
{character}
拆解这个prompt:
输入:一段多语种文档(Passage)和角色(Character)
使用 LLM(如 Qwen3-32B)生成:
- Character:对该文档感兴趣的角色(从 Persona Hub 中检索 Top-5 候选)
- Question_Type:角色可能提出的问题类型(如关键词、背景、摘要等)
- Difficulty:问题的难度等级(高中/大学/博士) 输出(JSON 格式):
{
"Character": "...",
"Question_Type": "...",
"Difficulty": "..."
}
- 查询生成阶段(Query Generation) 基于上述配置,LLM 生成一个自然语言查询(Query),用于构造 (query, document) 检索训练对。
template为:
Given a **Character**, **Passage**, and **Requirement**, generate a query from
the **Character**'s perspective that satisfies the **Requirement** and can
be used to retrieve the **Passage**. Please return the result in JSON
format.
Here is an example:
<example>
Now, generate the **output** based on the **Character**, **Passage** and
**Requirement** from user, the **Passage** will be in {corpus_language}
language, the **Character** and **Requirement** will be in English.
Ensure to generate only the JSON output, with the key in English and the value
in {queries_language} language.
**Character**
{character}
**Passage**
{passage}
**Requirment**
- Type: {type};
- Difficulty: {difficulty};
- Length: the length of the generated sentences should be {length} words;
- Languange: the language in which the results are generated should be
{language} language;
拆解这个prompt:
输入:
-
Character:一个角色设定,代表提问者的身份、兴趣或背景(如“a university student interested in ancient Chinese astronomy”)。
-
Passage:一段多语种文档,作为检索目标。
-
Requirement:一个结构化配置,包含: 输出:
-
仅输出 JSON 格式;
-
JSON 的 key 为英文,value 为指定语言;
-
查询必须从 Character 的视角出发,满足指定的 Requirement,并能用于检索该 Passage。
数据过滤
对每一对数据计算cosine相似度,选择相似度大于0.7的数据作为高质量数据。
数据
第一阶段 Weakly Supervised Pre-Traning
-
数据来源:合成数据
-
数量:150M( 1亿5千万) 第二阶段 Supervised Fine Tuning
-
数据来源:MS MARCO, NQ, HotpotQA, NLI, Dureader, T2 -Ranking, SimCLUE, MIRACL, MLDR, Mr.TyDi, Multi-CPR, CodeSearchNet .etc + 高质量合成数据
-
数量:有标签的数据:7M;合成数据:12M
评估和结果
Massive Multilingual Text Embedding Benchmark (MMTEB)
- Qwen3-Embedding-4B/8B 模型表现最好
- Qwen3-Embedding-0.6B 排在Gemini-Embedding之后,尽管只有0.6B的参数
消融实验
- 仅仅在合成数据上训练的Qwen3-Embedding-0.6B 比最后的Qwen3-Embedding-0.6B模型效果要好。
- 把弱监督阶段去掉的话,最后的性能会下降。
- 如果不进行合并,Qwen3-Embedding-0.6B 的性能会明显下降;
术语和概念
因果注意力(Causal Attention)
Causal attention是一种自回归注意力机制,模型在生成每个词时只能看到它之前的词。这种机制通过一个上三角的 attention mask 实现。
注意力机制的区别
Rerank 方法
- Point-wise
- Pair-wise
- List-wise
MRL
(略)
spherical linear interpolation 球状线性差值(slerp)
(略)
其他
- Persona Hub (地址:https://github.com/tencent-ailab/persona-hub) 我觉得这个项目很有意思,里面有3亿个拟人设定,例如环保主义者,历史学家,自然爱好者,老师,地理学家,学生,歌唱家等第。想象一下在虚拟世界里,这些人会干什么,会问什么问题?
随便看两个人物设定:
对罗马帝国感兴趣的历史学家:
A historian or a scholar who is interested in the history of the Roman Empire, particularly the early years and the impact of Christianity on society. They are knowledgeable about the persecution of Christians in the Roman Empire and the story of Saint Maurice, the Roman soldier who refused to participate in pagan sacrifices and was eventually martyred. They are also interested in the concept of honor, courage, and faithfulness to one’s beliefs, which are reflected in the story of Saint Maurice.
对医学术语感兴趣的人:
A person who is interested in medical terms and their meanings, particularly those related to cancer and medicine. They are likely to be a medical professional, a researcher, or a student who is studying the field of cancer biology. They are knowledgeable about the NCI Dictionary of Cancer Terms and are interested in learning more about parathyroid cancer and its related terms.
- 比对挖掘(bitext mining) 比对挖掘(Bitext Mining)是一种自动从不同语言的文本中找出互为翻译的句子对的技术。它广泛应用于机器翻译、跨语言信息检索、多语言语料构建等领域。
- 里面的Bitext 是bilingually aligned text。
- 例子