2025-06-13 论文阅读BGE-M3
发布于 2025年06月13日 • 2 分钟 • 312 字
Table of contents
论文地址:https://arxiv.org/abs/2402.03216
M3的意思是 Multi-Linguality, Multi-Functionality和Multi-Granularity
- 支持100种语言(multi-lingual, cross-lingual)
- 支持短句和长文档,最高到8192tokesn
- 支持不同的检索方法
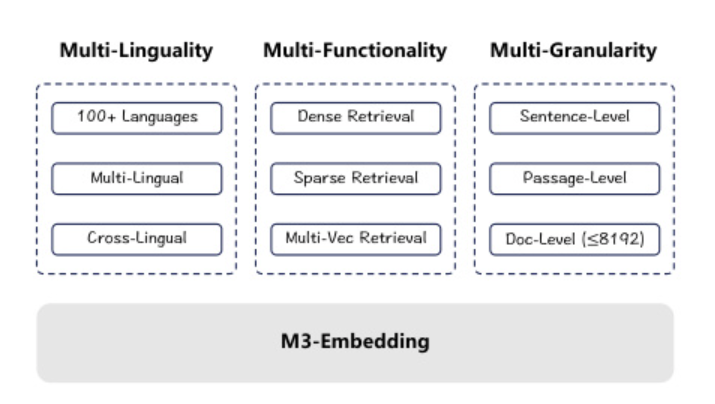
(图来源于论文)
Contribution
- 实现了自知识蒸馏,将来自不同检索功能的相关性分数集成到教师信号,从而提高训练质量。
- 优化了批处理策略,实现较大的批处理大小和高训练吞吐量,以提高Embedding的区分能力。
- 用data curation来得到高质量的数据
细节
不同的向量检索方法
- [CLS]用来做dense retrieval
- 其他token的向量用来做sparse retrieval 和multi-vector retrieval
Dataset sources
- extract the unsupervised data from massive multi-lingual corpora
- Integrate the closely related supervised data
- Synthesize the scarce data
Self-Knowledge Distillation
InfoNCE loss 的目标是最大化正样本对的相似度,同时最小化负样本对的相似度。
InfoNCE loss的计算
$$Loss= -log \frac{ \exp(sim(x_i,x_i^+)/\tau) }{\sum_{j=1}^K \exp(sim(x_i, x_i^{-j})/\tau) }$$
假设我们有一个数据集,其中每个样本 xi 有一个对应的正样本 $$x_i^+$$ 和多个负样本 $$x_i^{-1}, x_i^{-2}, …, x_i^{-K} $$。
对于每个样本 $$x_i$$,我们希望其与正样本 $$x_i^+ $$的相似度尽可能高。
$$x_i$$与所有负样本的相似度尽可能低。多目标训练时多个目标会产生冲突,所以本文提出了self-knowledge distillation。
用了Ensemble Learning 的的概念: $$L = (\lambda_1 L_{dense} + \lambda_2 L_{lex} + \lambda_3 L_{mul} + L_{inter})/4$$
Training Process
- XLM-RoBERTa is pre-trained with unsupervised data
- Self-Knowledge Distillation, three retrieval functionalities is fine-tuned with supervised data
- Synthesized data especially hard negative samples
Batching 批处理策略
Batchsize 必须很大,才能保证差异性。在有限的GPU资源的情况下,通常的做法是把输入数据切割成小序列来进行实验。但是M3-Embedding需要同时处理长文本和短序列。
优化策略
-
先将训练数据依据序列长度进行分组,生成小批量数据(mini-batch)时,从同一组里采样数据实例。——这种方法减少了padding操作,提升 GPU 的利用效率。
-
固定random seed,在做训练数据的采样的时候——这个可以保证各 GPU 分到的数据分布均衡,降低单个训练步骤中的等待时间。
-
处理长序列训练数据时,把 mini-batch 分成更小的子批次,借助梯度检查点技术依次编码各子批次并收集嵌入向量,能极大增加批量大小,降低内存占用。 例子:处理长度为 8192 的文本序列,初始批量大小可能受限于内存只能是 1。将其 mini-batch 分为 10 个子批次,每个子批次长度为 819.2(实际可能取整),利用梯度检查点依次编码每个子批次,最终收集所有嵌入向量,这样批量大小可能增大到 20 以上,相比原来提升了超 20 倍,有效利用有限内存完成更大规模训练。
-
在分布式环境下,把各 GPU 得到的嵌入向量进行广播,使每块 GPU 都能获取到全部嵌入向量,从而扩大在 batch 内可用于对比学习等任务的负样本规模。
-
MCLS (Multi-CLS)
实验
Multi-Lingual Retrieval
- 数据集:使用MIRACL (Zhang et al., 2023c) 数据集,包含18种语言的检索任务,每个任务都由查询和文档组成,查询和文档为同一种语言。
- 评估指标:主要使用nDCG@10作为评估指标,同时也计算了Recall@100的结果。
- 检索方法
- Baseline
- 结果
Cross-Lingual Retrieval
- 数据集:使用MKQA 数据集,包含25种非英语的查询。每个任务都由非英语的查询和英语的文档组成。文章里使用的数据集是经过处理之后的BEIR。
- 评估指标:使用Recall@100作为评估指标,同时也计算了Recall@20的结果。
- 结果
Multilingual Long-Doc Retrieval
- 数据集:
- Baseline: 除了前面的基线模型,还新增了长文本模型,例如JinaEmbeddingv2 和text-embedding-3-large。
- 评估指标:使用Recall@100作为评估指标,同时也计算了Recall@20的结果。
- 结果
Ablation study 消融实验
消融实验通过有选择地移除或修改系统中的某些部分,来观察这些变化对整体性能的影响。(消融实验是针对创新点的对照实验,通过对比来表明创新点的有效性)
- 为了探索self-knowledge distillation的影响,进行消融实验。
- 为了探索multi-stage-training的影响,进行消融实验。
- 为了探索M3-Embedding在长文档检索中的竞争力,进行了消融实验
术语和概念
Dense Retrieval(密集检索)
- 含义:密集检索是一种将文本映射到一个单一的嵌入向量(embedding)的检索方式。根据向量的相似度来进行检索。
- 用[CLS]或者mean-pooling dense retrieval, where relevant answers to the query can be retrieved based on the embedding similarity.
参考文献:Karpukhin et al., 2020;Xiong et al., 2020; Nee-lakantan et al., 2022; Wang et al., 2022; Xiao et al.,2023
Sparse/lexical Retrieval(稀疏检索)
- 含义:稀疏检索是根据文本中出现的词汇(token)来计算权重,并基于这些权重来进行检索。
- 它不会像密集检索那样将文本整体映射到一个向量,而是关注文本中的每一个词汇。例如,对于文本“今天天气很好”,它会分别计算“今天”“天气”“很”“好”这些词汇的权重。然后根据这些权重来衡量文本之间的相似度。比如,如果另一个文本中“天气”和“好”这两个词的权重也很高,那么这两个文本在稀疏检索中可能会被认为是相似的。
- weight通过relu来计算 参考文献:Gao et al., 2021a; Lin andMa,2021; Dai and Callan,2020
Multi-Vector Retrieval(多向量检索)
- 含义:多向量检索是使用多个向量来表示一个文本的检索方式。
- 与密集检索用一个向量表示文本不同,多向量检索会将文本分解成多个部分,每个部分用一个向量来表示。例如,对于一个长文本,可以将其分成几个段落,每个段落用一个向量来表示。或者对于一个复杂的概念,可以用多个向量从不同角度来表示。然后在检索时,会综合考虑这些向量来衡量文本之间的相似度。 参考文献:Khattaband Zaharia,2020
其他
为什么general text embedding发展如此迅速
-
预训练语言模型的普及,让文本的语义能够被很好地encode
-
Contrastive learning特别是negative sampling的发展
-
知识蒸馏的利用
-
学习多功能的嵌入模型变得越来越流行,这些模型能够统一支持各种应用场景
-
预训练语言模型的普及,让文本的语义能够被很好地encode
-
Contrastive learning特别是negative sampling的发展
-
知识蒸馏的利用
-
学习多功能的嵌入模型变得越来越流行,这些模型能够统一支持各种应用场景
如何将向量模型从English拓展到multi-lingual
- 预训练多语言文本编码器(Pretrained multi-lingual text-encoders)的发展,例如 mBERT (Pires et al., 2019), mT5 (Xue et al., 2021), XLM-R (Conneau et al., 2020)
- 多语言语料的发展,例如MIRACL (Zhang et al., 2023c), mMARCO (Bonifacio et al., 2021), Mr. TyDi (Zhang et al., 2021b), MKQA(Longpreetal., 2021).
- 多语言嵌入模型的发展,例如mDPR (Zhang et al., 2023b), mContriever (Izacard et al., 2022), mE5 (Wang et al., 2022)